

PythonPro #49: Cool Python 3.13 Features, Azure LLM Deployment, and Great Expectations vs Pandas profiling

Welcome to a brand new issue of PythonPro!
In today’s Expert Insight we bring you an excerpt from the recently published book, Python Data Cleaning and Preparation Best Practices, which compares Pandas profiling and Great Expectations for data profiling and analysis.
News Highlights: DJP a Pluggy-based plugin system for Django launches, easing integration; and PondRAT malware, hidden in Python packages, targets developers in a supply chain attack.
Here are my top 5 picks from our learning resources today:
Deploy Python LLM Apps on Azure Web App (GPT-4o Azure OpenAI and SSO auth)🤖
Data Visualization with Matplotlib and Seaborn - A Comprehensive Guide to Plot Types🎨
The Anna Karenina Principle in Code Quality - Addressing PySpark Challenges with PyASTrX🔥
And, today’s Featured Study, introduces sbijax, a Python package built on JAX for efficient neural simulation-based inference (SBI), offering a wide range of algorithms, a user-friendly interface, and tools for efficient and scalable Bayesian analysis.
Stay awesome!
Divya Anne Selvaraj
Editor-in-Chief
P.S.: This month's survey is now live, do take the opportunity to leave us your feedback, request a learning resource, and earn your one Packt credit for this month.
🐍 Python in the Tech 💻 Jungle 🌳

🗞️News
DJP - A plugin system for Django: This new system based on Pluggy, simplifies plugin integration by automating configuration. Read to learn how to set up DJP, create plugins, and view examples like
django-plugin-blog.New PondRAT Malware Hidden in Python Packages Targets Software Developers: North Korean-linked threat actors are using poisoned Python packages to gain access to supply chains via developers' systems.
💼Case Studies and Experiments🔬
Python for Inversive and Hyperbolic Geometry: Introduces a Python library which provides classes and utilities for visualizing inversive and hyperbolic geometry using the Poincaré disc model.
Detecting Marathon Cheaters - Using Python to Find Race Anomalies: Covers scraping race data, using speed thresholds and z-scores to filter participants with "superhuman" splits, and analyzing these splits for suspicious activity.
📊Analysis
Python 3.13: Cool New Features for You to Try: Releasing today, Python 3.13, introduces several improvements, including an enhanced REPL, clearer error messages, and progress on removing the GIL).
Understanding Inconsistencies in IP Address Classification Across Programming Languages: Discusses how these inconsistencies can cause security vulnerabilities, particularly in cloud environments prone to SSRF.
🎓 Tutorials and Guides 🤓

🎥Deploy Python LLM Apps on Azure Web App (GPT-4o Azure OpenAI and SSO auth): Explains how to deploy a Streamlit web application into Azure Cloud using Azure App Service Plan and Azure Web App.
How Data Platforms Work: Uses Python with Apache Arrow to demonstrate data models, builds an example data system through query plans, and provides code examples for creating, filtering, and projecting datasets.
Data Visualization with Matplotlib and Seaborn - A Comprehensive Guide to Plot Types: Covers line plots, bar plots, scatter plots, histograms, box plots, heatmaps, and pair plots, each illustrated with examples.
Instrumenting CPython with DTrace and SystemTap: Covers enabling embedded markers (or probes) in CPython for tracing function calls, garbage collection, and module imports and provides examples and scripts.
Forecasting in Excel using Techtonique's Machine Learning APIs under the hood: discusses how to use Techtonique's machine learning APIs through Excel for tasks like forecasting, data visualization, and predictive analytics.
Implementing Anthropic's Contextual Retrieval with Async Processing: Explains Anthropic's Contextual Retrieval technique, which enhances RAG systems by adding context to document chunks to improve search accuracy.
What’s Inside a Neural Network?: Explains how to visualize the error surface of a neural network using PyTorch and Plotly by walking you through from generating synthetic data to visualizing training steps.
🔑Best Practices and Advice🔏

What Can A Coffee Machine Teach You About Python's Functions?: Explains how Python functions work, from defining parameters to calling functions and handling return values, through an accessible, relatable analogy.
Refactoring Python with 🌳 Tree-sitter & Jedi: Explores a method to refactor Python code across multiple files by renaming a
pytestfixture usingTree-sitterto parse function definitions andJedito rename identifiers.Ensuring a block is overridden in a Django template: Shows how to prevent missing titles in Django templates by adding a custom template tag that raises an exception if a block is not overridden.
The Anna Karenina Principle in Code Quality - Addressing PySpark Challenges with PyASTrX: Discusses how to identify and block bad coding practices in PySpark, such as using
withColumnwithin loops.What is a Pure Function in Python?: Explains pure functions in Python, which produce the same output for the same input without affecting external variables and enable writing clean, predictable, and easy-to-test code.
🔍Featured Study: Simulation-based Inference with the Python Package sbijax💥
"Simulation-based Inference with the Python Package sbijax" by Dirmeier et al., introduces sbijax, a Python package for neural simulation-based inference (SBI). The paper outlines the package’s implementation of advanced Bayesian inference methodologies using JAX for computational efficiency.
Context
SBI is a technique for Bayesian inference when the likelihood function is too complex to compute directly. By using neural networks as surrogates, SBI approximates complex Bayesian posterior distributions, which describe the probability of model parameters given observed data. Neural density estimation, a modern approach to SBI, refers to using neural networks to model these complex distributions accurately. The sbijax package enables this inference process by offering a range of neural inference methods, and it is built on JAX. JAX is a Python library that provides efficient automatic differentiation and parallel computation on both CPUs and GPUs. This makes sbijax particularly relevant for statisticians, data scientists, and modellers working with complex Bayesian models.
Key Features of sbijax
Wide Range of SBI Algorithms: sbijax implements state-of-the-art methods, including Neural Likelihood Estimation (NLE), Neural Posterior Estimation (NPE), Neural Likelihood-Ratio Estimation (NRE), and Approximate Bayesian Computation (ABC).
Computational Efficiency with JAX: Written entirely in JAX, sbijax achieves rapid neural network training and parallel execution on hardware like CPUs and GPUs, often outperforming PyTorch.
User-Friendly Interface: Provides simple APIs to construct and train models, simulate data, perform inference, and visualise results.
Diagnostic Tools: Offers model diagnostics and visualisation via ArviZ
InferenceDataobjects for easy exploration and analysis of posterior samples.Flexible Model Specification: Supports customisable neural networks and integration with the broader JAX ecosystem for advanced model building.
What This Means for You
sbijax is most useful for computational modellers, data scientists, and statisticians who require efficient and flexible tools for Bayesian inference. Its user-friendly interface, coupled with computational efficiency, makes it practical for those working with high-dimensional or complex simulation models.
Examining the Details
The authors validate sbijax by showcasing its implementation in different SBI methods and comparing performance against conventional tools. The package provides sequential inference capabilities, combining both neural density estimation techniques and traditional ABC. The authors demonstrate sbijax’s functionality by training models using real and synthetic data, then sampling from the posterior distributions. In a benchmark example with a bivariate Gaussian model, sbijax successfully approximates complex posterior distributions using various algorithms like NLE and SMC-ABC.
The paper details the efficiency and accuracy of sbijax, backed by empirical evaluations that show JAX's computational advantage over other libraries like PyTorch. Its consistent performance across various SBI tasks underscores its reliability and broad applicability in Bayesian analysis.
You can learn more by reading the entire paper or accessing the sbijax documentation here.
🧠 Expert insight💥

Here’s an excerpt from “Chapter 3: Data Profiling – Understanding Data Structure, Quality, and Distribution” in the book, Python Data Cleaning and Preparation Best Practices by Maria Zervou, published in September 2024.
Comparing Great Expectations and pandas profiler – when to use what
Pandas profiling and Great Expectations are both valuable tools for data profiling and analysis, but they have different strengths and use cases.
Here’s a comparison between the two tools.
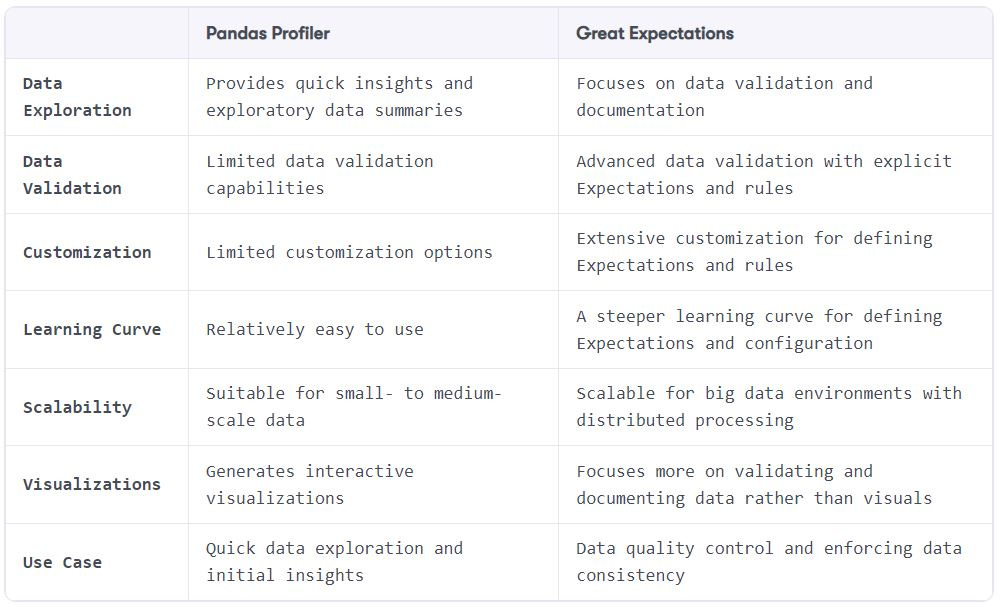
Table 3.2 – Great Expectations and pandas profiler comparison
Pandas profiling is well suited for quick data exploration and initial insights, while Great Expectations excels in data validation, documentation, and enforcing data quality rules. Pandas profiling is more beginner-friendly and provides immediate insights, while Great Expectations offers more advanced customization options and scalability for larger datasets. The choice between the two depends on the specific requirements of the project and the level of data quality control needed.
As the volume of data increases, we need to make sure that the choice of tools we’ve made can scale as well. Let’s have a look at how we can do this with Great Expectations.
Great Expectations and big data
Distributed processing frameworks: Great Expectations integrates seamlessly with popular distributed processing frameworks, such as Apache Spark. By leveraging the parallel processing capabilities of these frameworks, Great Expectations can distribute the data validation workload across a cluster, allowing for efficient processing and scalability.
Partitioning and sampling: Great Expectations simplifies the process of partitioning and sampling large datasets and enhancing performances and scalability. Unlike the manual partitioning required in tools such as pandas profiling, Great Expectations automates the creation of data subsets or partitions for profiling and validation. This feature allows you to validate specific subsets or partitions of the data, rather than processing the entire dataset at once. By automating the partitioning process, Great Expectations streamlines the profiling workflow and eliminates the need for manual chunk creation, saving time and effort.
Incremental validation: Instead of revalidating the entire big dataset every time, Great Expectations supports incremental validation. This means that as new data is ingested or processed, only the relevant portions or changes need to be validated, reducing the overall validation time and effort. This is a great trick to reduce the time it takes to check the whole data and optimize for cost!
Caching and memoization: Great Expectations incorporates caching and memoization techniques to optimize performance when repeatedly executing the same validations. This can be particularly beneficial when working with large datasets, as previously computed results can be stored and reused, minimizing redundant computations.
Cloud-based infrastructure: Leveraging cloud-based infrastructure and services can enhance scalability for Great Expectations. By leveraging cloud computing platforms, such as AWS or Azure, you can dynamically scale resources to handle increased data volumes and processing demands
Efficient data storage: Choosing appropriate data storage technologies optimized for big data, such as distributed file systems or columnar databases, can improve the performance and scalability of Great Expectations. These technologies are designed to handle large-scale data efficiently and provide faster access for validation and processing tasks.
Note
While Great Expectations offers scalability options, the specific scalability measures may depend on the underlying infrastructure, data storage systems, and distributed processing frameworks employed in your big data environment.
Packt library subscribers can continue reading the entire book for free. You can buy Python Data Cleaning and Preparation Best Practices, here.
Get the eBook for $35.99 $24.99!
Other Python titles from Packt at 30% off


Get the eBook for $27.99 $18.99!

Get the eBook for $35.99 $17.99!
And that’s a wrap.
We have an entire range of newsletters with focused content for tech pros. Subscribe to the ones you find the most useful here. The complete PythonPro archives can be found here.
If you have any suggestions or feedback, or would like us to find you a Python learning resource on a particular subject, take the survey or leave a comment below!